
Les IA génératives, c’est le grand sujet d’aujourd’hui, et sûrement de demain ! ChatGPT et consorts sont encore jugés sévèrement en ce qui concerne leur style : à moins d’être étroitement encadrées, elles produisent des textes assez indigestes :
- phrases trop longues (ou trop courtes !) ;
- lourdeurs de style ;
- abus de connecteurs logiques ;
- etc.
Mais qu’en est-il de leur aptitude technique en ce qui concerne l’intégration de mots-clés SEO ? Ce critère est d’importance : pour créer une page ou un article qui ait une chance de bien se positionner dans la SERP, vous devez intégrer des mots-clés spécifiques. Des outils comme 1.fr, YourTextGuru ou encore Semji permettent d’avoir une bonne idée des termes à intégrer par rapport à une requête principale.
Pour un humain, cet effort d’intégration nécessite beaucoup de temps et plusieurs relectures. C’est pour ce type de tâches, assez fastidieuses, que les IA peuvent être d’un grand secours.
Lyndra-Good a donc souhaité tester les aptitudes d’intégration de mots-clés des IA génératives. Cet article vous présente cet examen, sa méthodologie et ses principaux résultats.
1. Méthodologie
1.1 IA candidates
Dans un premier temps, il fallait des candidats, retenus suivant ces 2 critères :
- IA propriétaire (pas d’applications tierces fonctionnant grâce à des API)
- Utilisable gratuitement
Nous avons donc retenu les 6 IA génératives suivantes :
- ChatGPT 4o (Open AI)
- Gemini (Google)
- Copilot (Bing)
- Claude 3.5 (Anthropic)
- Le Chat (Mistral AI)
- Perplexity (Perplexity AI)
1.2 Sujets d'articles
Il fallait ensuite des sujets d’articles concrets pour faire passer le test aux IA. Pour ce faire, nous avons simplement demandé à chaque IA 3 sujets intéressants à traiter pour notre test d’aptitude. En éliminant les doublons, nous avons obtenu 11 sujets :
- Les bienfaits de la méditation pour la santé mentale
- L’impact de l’IA sur les emplois du futur
- Les meilleures destinations écoresponsables en 2024
- Les avantages et inconvénients des voitures électriques pour l’environnement
- Comment préparer un gâteau au chocolat moelleux
- L’impact des réseaux sociaux sur la santé mentale des adolescents
- Les tendances culinaires émergentes pour l’année à venir
- L’évolution des tendances de la mode au fil des décennies
- Les meilleures méthodes pour apprendre une nouvelle langue
- Les meilleures destinations pour des vacances en famille en été
- Les bienfaits du yoga pour la santé mentale et physique
Nous avons ensuite décidé de laisser le dernier mot… à l’humain : un rapide sondage sur LinkedIn nous a permis de sélectionner 3 sujets à soumettre aux IA :
- L’impact de l’IA sur les emplois du futur
- L’impact des réseaux sociaux sur la santé mentale des adolescents
- Les tendances culinaires émergentes pour l’année à venir
1.3 Prompt
Nous avons utilisé un prompt assez basique pour générer les articles :
Tu vas créer un article de XX mots sur le sujet XX. Cet article doit être optimisé pour le référencement naturel. Voici une liste de mots-clés à intégrer dans cet article :
Mots-clés principaux :
- …
- …
- …
Mots-clés secondaires :
- …
- …
- …
Les mots-clés principaux doivent être utilisés dans les titres (h1, h2, h3…) et le corps du texte. Les mots-clés secondaires doivent surtout être utilisés dans le corps du texte. Chacun de ces mots-clés doit être utilisé en respectant le genre (masculin ou féminin) et le nombre (singulier ou pluriel) indiqués.
Pour commencer, rédige un plan pour cet article.
Rédige l’introduction en prenant soin d’intégrer des mots-clés.
Rédige le premier h2 en prenant soin d’intégrer des mots-clés.
Etc.
1.4 Outil SEO
Pour déterminer les mots-clés à intégrer, nous avons utilisé YourTextGuru. Outre les mots-clés, l’outil nous a aussi permis, pour chaque article, de déterminer le nombre de mots à produire, en examinant les concurrents de la SERP.
1.5 Déroulement du test et problèmes rencontrés
Le test s’est bien déroulé, à 2 problèmes près.
1.5.1 Verbiage incontrôlé : quand les IA explosent les limites de mots
Claude 3.5, Le Chat et Perplexity se sont montrés beaucoup trop loquaces lors du premier sujet d’article. La limite définie en début de prompt n’a pas suffi à circonscrire leur élan et ces 3 IA ont livré de véritables pavés (voir détails sur le nombre de mots rédigés en 2ème partie).
Par souci d’équité, nous avons conservé le prompt du premier sujet tel quel pour toutes les IA. En revanche, pour les deux autres sujets, nous avons enrichi le prompt en fournissant, pour chaque nouvelle section à rédiger, une fourchette de mots.
1.5.2 Mémoire limitée de Copilot
Le modèle d’IA générative de Bing, Copilot, nous a semblé un peu limité pour ce test. Au bout de 4 à 5 questions, l’IA indique qu’elle a atteint sa limite, et qu’il faut commencer une nouvelle conversation. Nous sommes alors forcés de préciser à nouveau l’intégralité du prompt et des mots-clés.

Ce problème introduit un biais dans le test : Copilot ne sait pas quels mots-clés il a déjà intégré lors des précédentes conversations.
La mémoire limitée de cette IA (en tous cas, en version gratuite) semble la disqualifier pour une utilisation professionnelle par des créateurs de contenu.
2. Résultats
2.1 Article 1 : L'impact de l'IA sur les emplois du futur
ChatGPT 4o
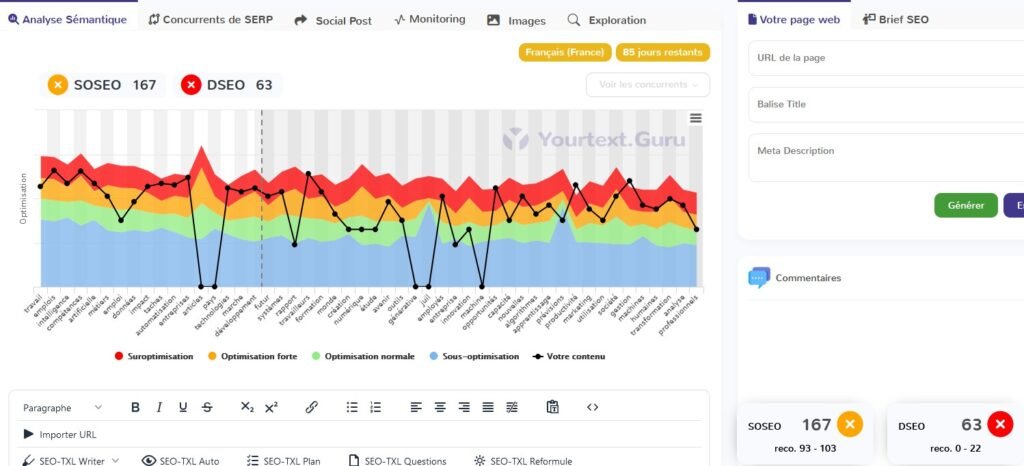
Gemini

Copilot
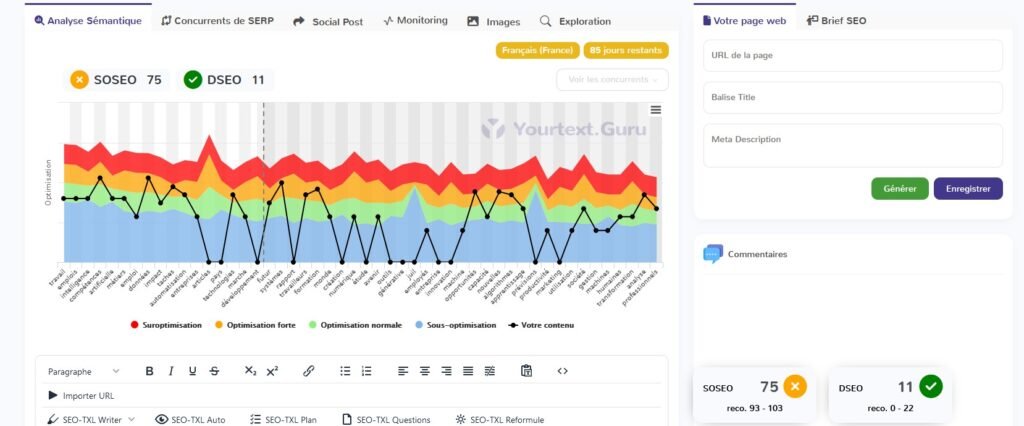
Claude 3.5
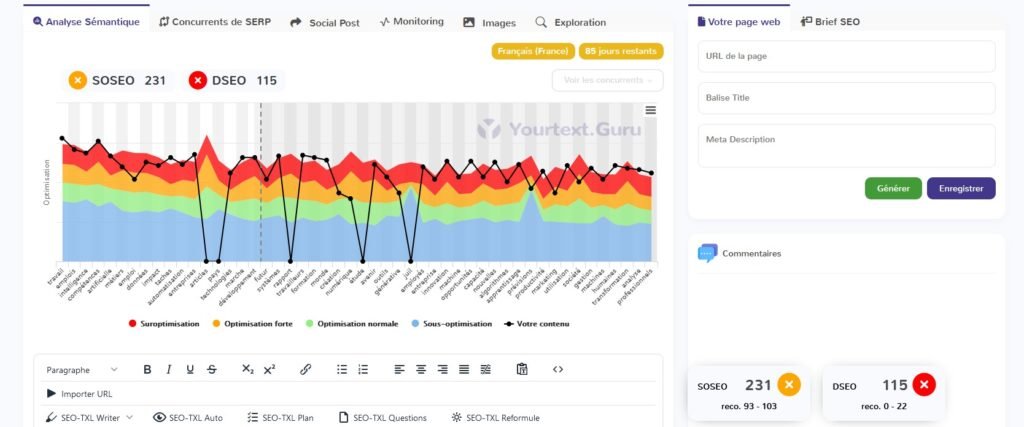
Le Chat
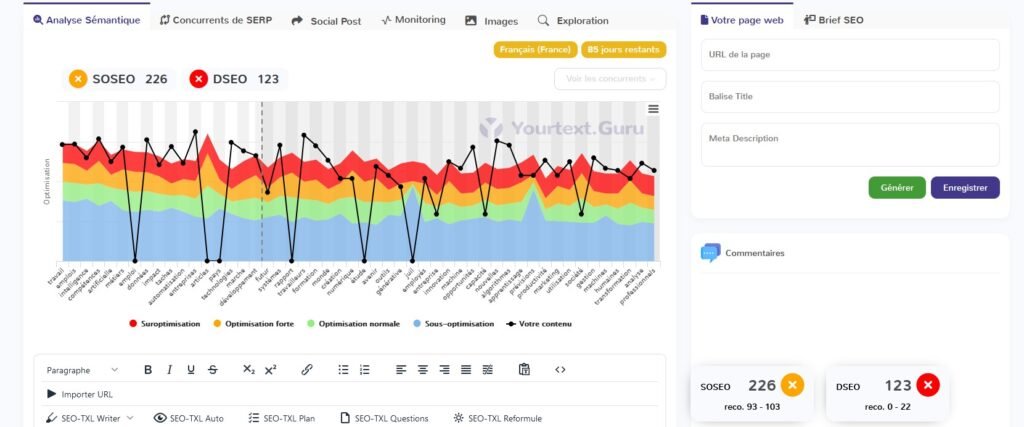
Perplexity
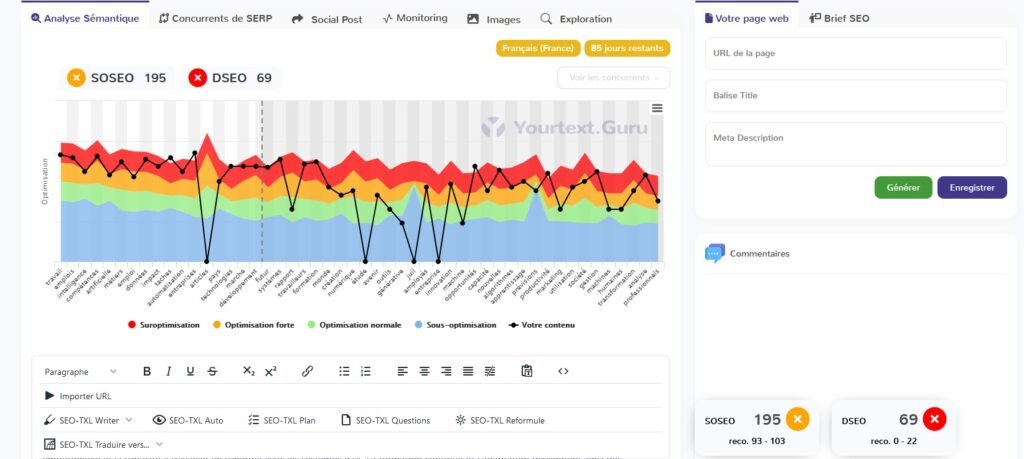
2.2 Article 2 : L'impact des réseaux sociaux sur la santé mentale des adolescents
Chat GPT 4o

Gemini

Copilot

Claude 3.5
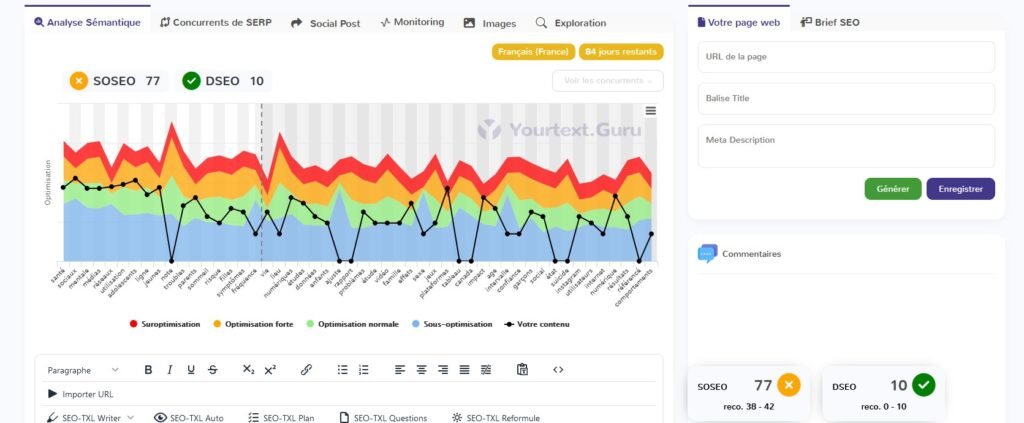
Le Chat
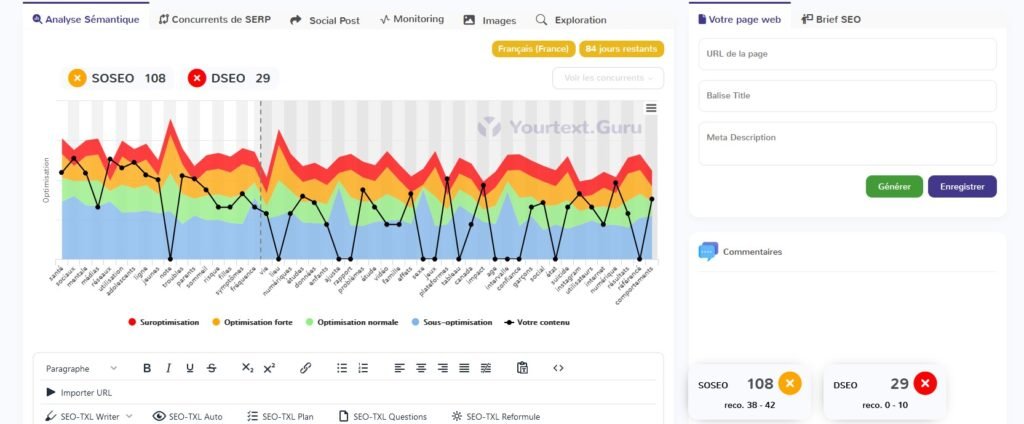
Perplexity
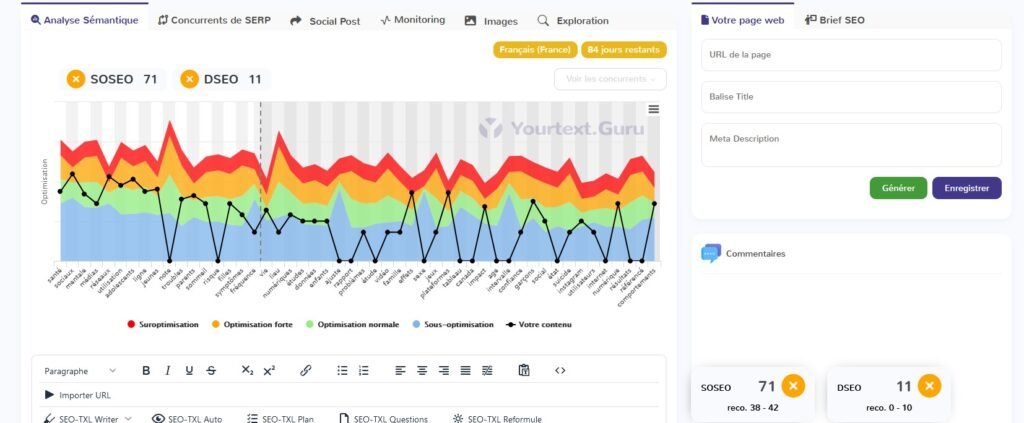
2.3 Article 3 : Les tendances culinaires émergentes pour l'année à venir
Chat GPT 4o
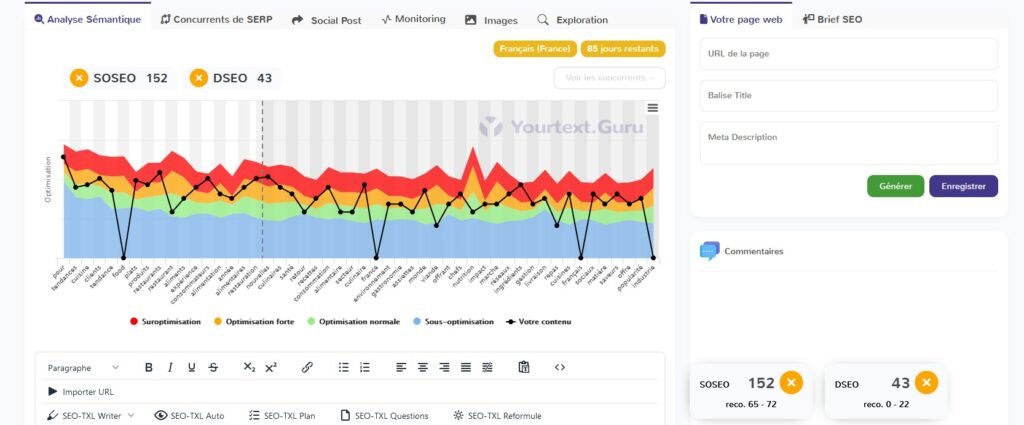
Gemini
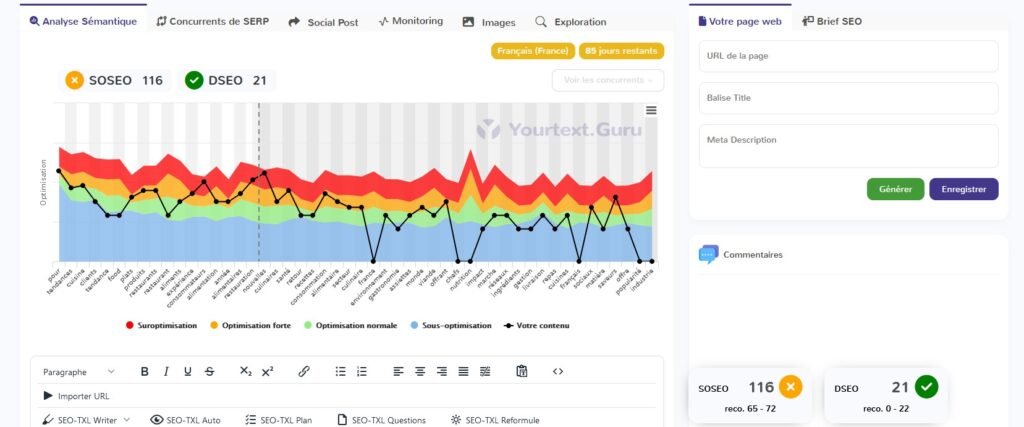
Copilot
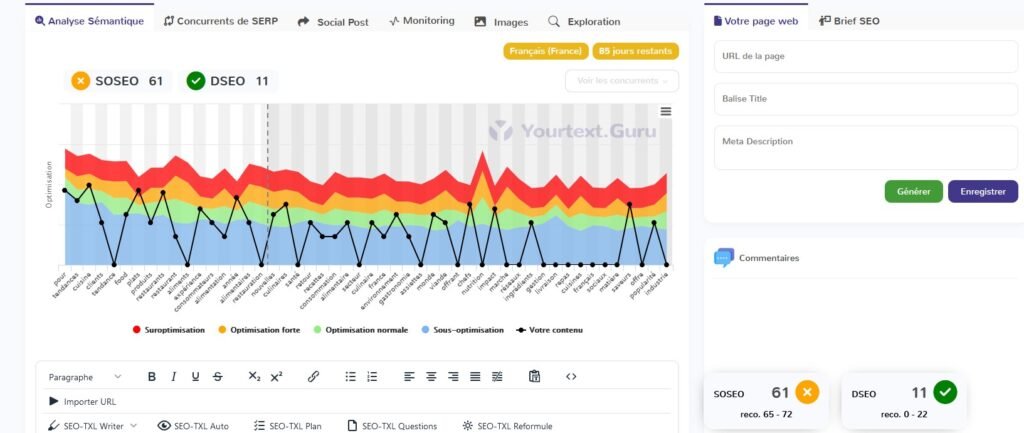
Claude 3.5
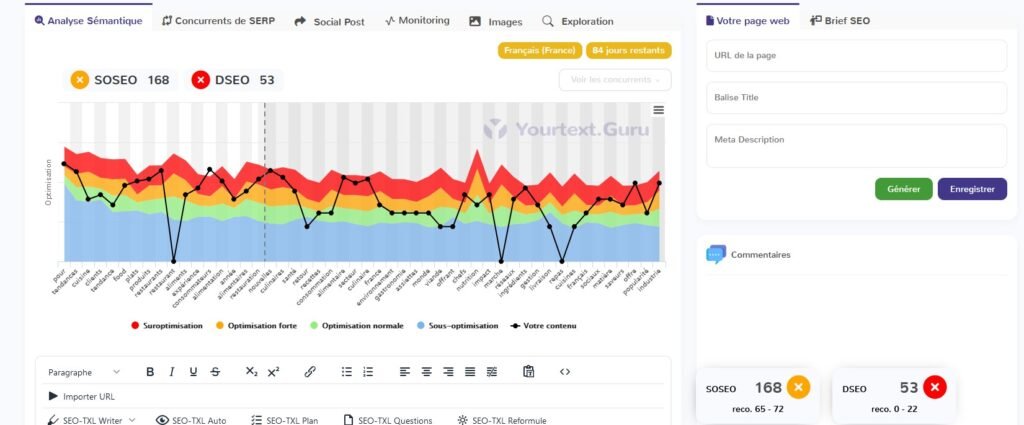
Le Chat

Perplexity

3. Analyse des résultats
3.1 Respect du nombre de mots demandé
Dans le cadre d’un test d’IA générative, le respect du nombre de mots demandé est un critère important pour évaluer la capacité de l’IA à répondre précisément aux consignes.
En production de contenu, que ce soit pour le SEO, la rédaction d’articles, ou d’autres usages, il est crucial de rester dans une certaine limite de mots pour respecter des contraintes éditoriales, marketing ou encore pour s’adapter à des formats spécifiques.
Le non-respect de ces limites peut entraîner des problèmes de cohérence, de densité informative et même nuire à l’expérience utilisateur.
3.1.1 Tableau récapitulatif : nombre de mots produits par chaque IA
| IA | Article 1 (2000 mots) | Article 2 (2000 mots) | Article 3 (1500 mots) |
| ChatGPT4o | 2909 | 2045 | 1744 |
| Gemini | 1821 | 1842 | 1311 |
| Copilot | 1374 | 1662 | 1072 |
| Claude 3.5 | 5871 | 1927 | 1545 |
| Le Chat | 6041 | 2783 | 1960 |
| Perplexity | 4756 | 1715 | 2274 |
3.1.2 Remarques
L’analyse des résultats de ce tableau met en évidence la performance des différentes IA génératives face à la contrainte du respect du nombre de mots.
Pour le premier article, toutes les IA ont eu pour consigne de produire un texte de 2000 mots. Les résultats montrent des écarts significatifs. Par exemple, Claude 3.5, Le Chat et Perplexity ont largement dépassé la limite. Seul Gemini s’est distingué.
À partir du deuxième article, le prompt a été enrichi avec des indications plus précises, en fournissant une fourchette de mots pour chaque section du texte. Cet ajustement a permis de mieux encadrer la production de contenu. Nous avons observé une amélioration globale de la conformité des IA aux exigences :
- Le Chat a continué à produire des textes bien au-delà des attentes, même avec ces indications supplémentaires ;
- Claude 3.5 et ChatGPT 4o sont très proches des limites fixées à partir du moment où on leur donne des indications supplémentaires ;
- Perplexity a un comportement plus erratique avec ces consignes : sous ou surproduction.
- Gemini, dont la performance était très bonne sans consigne supplémentaire, ne s’améliore pas avec le prompt affiné.
3.1.3 Les vainqueurs ?
En résumé, Gemini est l’IA qui s’en sort le mieux en respectant le nombre de mots demandé, que ce soit avec ou sans rappel précis pour chaque section. Claude 3.5 et GPT4o montrent une meilleure précision lorsque des consignes leur sont données progressivement au cours de la rédaction.
3.2 Respect des scores SOSEO et DSEO de YourTextGuru
Nous allons évaluer à présent les performances des IA génératives en termes de respect des scores SOSEO et DSEO, tels que définis par YourTextGuru.
Le SOSEO (Score d’Optimisation SEO) mesure l’efficacité d’un texte à répondre aux exigences des moteurs de recherche pour un bon référencement.
Le DSEO (Danger SEO), quant à lui, évalue les risques de sur-optimisation ou de pratiques pouvant nuire à la visibilité du contenu.
3.2.1 Tableau récapitulatif : delta par rapport à la préconisation YourTextGuru
| IA | SOSEO Article 1 | DSEO article 1 | SOSEO Article 2 | DSEO Article 2 | SOSEO Article 3 | DSEO Article 3 |
| ChatGPT4o | + 62 % | + 286 % | + 109 % | + 50 % | + 111 % | + 95 % |
| Gemini | – 2 % | 0 | + 57 % | 0 | + 61 % | 0 |
| Copilot | – 20 % | 0 | + 35 % | 0 | – 6 % | 0 |
| Claude 3.5 | + 124 % | + 422 % | + 83 % | 0 | + 133 % | + 141 % |
| Le Chat | + 119 % | + 459 % | + 157 % | + 190 % | + 153 % | + 236 % |
| Perplexity | + 89 % | + 213 % | + 69 % | + 10 % | + 125 % | + 123 % |
3.2.2 Remarques
Pour être optimisé, c’est optimisé ! A l’exception de Copilot, toutes les IA atteignent, voire dépassent largement le score d’optimisation pour chaque article.
Problème : le score de danger SEO est également très souvent dépassé :
- dans des limites délirantes par ChatGPT 4o, Claude 3.5, Le Chat et Perplexity pour le premier article ;
- avec des scores encore beaucoup trop importants pour Le Chat dans les articles 2 et 3
3.2.3 Les vainqueurs ?
Gemini est l’IA la plus équilibrée pour le respect des préconisations YourTextGuru. L’IA de Google atteint (Article 1) ou dépasse raisonnablement (Articles 2 et 3) le score d’optimisation SEO. Elle respecte également le score de danger SEO pour tous les articles.
En somme, c’est l’IA qui nécessite le moins de travail humain en termes d’optimisation SEO après un premier jet.
3.3 Richesse lexicale brute
Nous examinons ensuite la façon dont les IA utilisent effectivement les mots-clés demandés.
3.3.1 Tableaux récapitulatifs
Nombre de mots-clés principaux utilisés
| IA | Article 1 | Article 2 | Article 3 |
| ChatGPT4o | 15/17 | 16/17 | 16/17 |
| Gemini | 15/17 | 15/17 | 17/17 |
| Copilot | 14/17 | 14/17 | 14/17 |
| Claude 3.5 | 15/17 | 16/17 | 16/17 |
| Le Chat | 14/17 | 16/17 | 15/17 |
| Perplexity | 16/17 | 15/17 | 17/17 |
Nombre de mots-clés secondaires utilisés
| IA | Article 1 | Article 2 | Article 3 |
| ChatGPT4o | 30/33 | 24/33 | 30/33 |
| Gemini | 26/33 | 20/33 | 27/33 |
| Copilot | 23/33 | 14/33 | 17/33 |
| Claude 3.5 | 30/33 | 26/33 | 31/33 |
| Le Chat | 30/33 | 22/33 | 31/33 |
| Perplexity | 30/33 | 21/33 | 31/33 |
3.3.2 Remarques
Toutes les IA sont proches de la perfection en termes d’utilisation des mots-clés principaux. Seul Copilot est légèrement à la traîne, mais dans des proportions très raisonnables.
On note quelques étrangetés, comme Le Chat, qui malgré un total de mots démesuré dans l’article 1, ne reprend que 14 des 17 mots-clés principaux.
Pour les mots-clés secondaires, les IA se montrent également assez efficaces. Seul l’article 2 leur pose quelques difficultés.
3.4 Optimisation, sur-optimisation et sous-optimisation des mots-clés
Voici un nouveau critère décisif de notre test. Si toutes les IA parviennent à utiliser la majorité des mots-clés demandés, elles se distinguent largement en termes d’optimisation.
3.4.1 Tableaux récapitulatifs
Nombre de mots-clés utilisés dans la zone optimisation normale ou forte
| IA | Article 1 | Article 2 | Article 3 |
| ChatGPT4o | 17/50 | 29/50 | 30/50 |
| Gemini | 30/50 | 25/50 | 31/50 |
| Copilot | 30/50 | 20/50 | 17/50 |
| Claude 3.5 | 7/50 | 33/50 | 22/50 |
| Le Chat | 6/50 | 25/50 | 17/50 |
| Perplexity | 19/50 | 27/50 | 23/50 |
Nombre de mots-clés en sous-optimisation
| IA | Article 1 | Article 2 | Article 3 |
| ChatGPT4o | 7/50 | 18/50 | 6/50 |
| Gemini | 17/50 | 25/50 | 14/50 |
| Copilot | 20/50 | 29/50 | 30/50 |
| Claude 3.5 | 5/50 | 15/50 | 6/50 |
| Le Chat | 6/50 | 18/50 | 5/50 |
| Perplexity | 7/50 | 22/50 | 7/50 |
Nombre de mots-clés en sur-optimisation
| IA | Article 1 | Article 2 | Article 3 |
| ChatGPT4o | 24/50 | 3/50 | 15/50 |
| Gemini | 4/50 | 1/50 | 5/50 |
| Copilot | 1/50 | 0/50 | 4/50 |
| Claude 3.5 | 38/50 | 2/50 | 21/50 |
| Le Chat | 38/50 | 8/50 | 28/50 |
| Perplexity | 25/50 | 3/50 | 21/50 |
3.4.2 Remarques
Gemini est la seul IA qui parvient pour chaque article à positionner au moins la moitié des mots-clés dans la zone d’optimisation normale ou forte de YourTextGuru.
ChatGPT 4o reste compétitif puisqu’il y parvient pour 2 articles sur 3.
Pour le reste, ça n’est pas brillant : les 4 autres IA atteignent ce score uniquement sur un article.
Il faut également s’attarder sur la sur-optimisation. Dans le cadre de la création de contenu SEO, elle est plus gênante que la sous-optimisation : il est facile d’ajouter des phrases avec des mots-clés manquants mais il est plus fastidieux de supprimer des mots-clés en trop grand nombre.
A ce titre, ChatGPT 4o, Le Chat, Claude 3.5 et Perplexity peuvent donner du fil à retordre aux rédacteurs web et autres créateurs de contenu : ils dépassent les 10 mots-clés en suroptimisation pour 2 articles sur 3.
3.4.3 Un vainqueur ?
Une fois de plus, Gemini nous paraît être l’IA la plus équilibrée. Malgré une loquacité beaucoup plus raisonnable que certaines de ses consœurs, l’IA de Google atteint des scores d’optimisation normale ou forte pour la moitié ou plus des mots-clés demandés à chaque article !
La performance est d’autant plus intéressante que le reste des mots-clés est pour l’essentiel en sous-optimisation, ce qui facilite le travail de retouche.
4. Verdict et limites du test
4.1 Palmarès
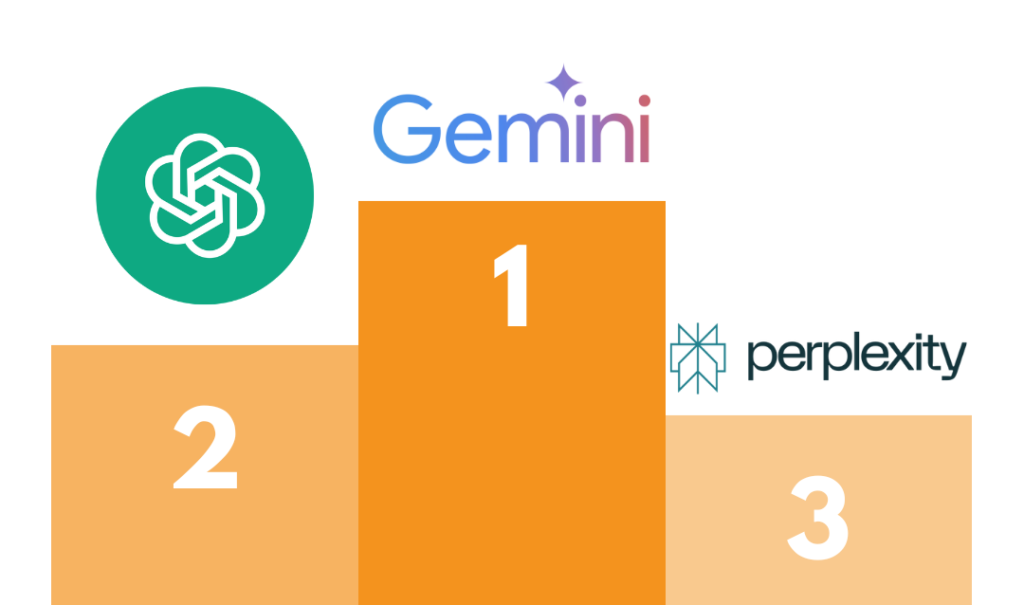
La ferveur chauvine des JO n’étant pas tout à fait terminée, nous aurions préféré primer Le Chat de Mistral ! Mais le test laisse clairement apparaître que Gemini est la meilleure IA au niveau des aptitudes d’intégration de mots-clés SEO.
Les points forts de Gemini :
- Respect du nombre de mots demandés dans une consigne ;
- Score DSEO jamais dépassé ;
- Score SOSEO respecté ou raisonnablement dépassé ;
- Couverture lexicale satisfaisante ;
- Capacité à positionner au moins la moitié des mots-clés en optimisation normale ou forte.
En somme, le leader des moteurs de recherche a produit une IA efficace pour l’optimisation sémantique ! Nous n’irons pas jusqu’à dire que c’est logique et attendu, mais c’est en tous cas à souligner.
Le podium pourrait être complété par ChatGPT 4o, plus raisonnable que les autres en termes de suroptimisation.
La 3ème place est plus difficile à attribuer : à la vue des différents scores, nous l’aurions accordé à Copilot si cette IA disposait d’une plus grande mémoire conversationnelle. A défaut, cela se joue entre Claude 3.5 et Perplexity, que nous privilégions car il a une tendance moindre à la suroptimisation.
4.3 Limites du test
Attention : notre test n’est pas parfait, et voici pourquoi.
4.3.1 Echantillon limité
Évaluer les IA sur seulement 3 articles n’est certainement pas suffisant, mais donne tout de même un bon aperçu de leurs capacités.
Pour éviter les différents biais, porter l’échantillon à 10 articles pourrait être intéressant.
4.3.2 Manque de calculs
Par ailleurs, Lyndra-Good est une agence web, par un bureau d’études statistiques : nous ne nous sommes pas lancés dans des calculs pour analyser la causalité entre une trop grande production écrite et un large dépassement des scores d’optimisation. A lire les chiffres, il y a au moins corrélation entre ces deux facteurs !
4.3.3 Prompt à revoir ?
Pour optimiser les résultats fournis par les IA génératives, le prompt engineering est indispensable. Nous ne sommes pas spécialistes en la matière, raison pour laquelle nous nous sommes contentés d’un prompt relativement simple.
Il est sûrement possible d’améliorer les résultats grâce à des prompts plus précis, une meilleure explication des attentes et davantage de contexte.
Le but était de se mettre à la place de la majeure partie des créateurs de contenu, est de voir quelle IA était la plus satisfaisante avec des consignes basiques.
4.4.4 Objectivité ?
Nous nous sommes efforcés de rester objectifs dans ce test. Mais les critères que nous avons choisi ne sont pas nécessairement adaptés à tous. Peut-être que certains créateurs de contenus auraient accordé une moindre importance à certains items, et un poids supérieur à d’autres…
Nous espérons que ce test vous a intéressé ! A vous de nous dire, en commentaire, si les résultats vous incitent à essayer des modèles différents pour la création de contenu SEO…